MSteineke

A few weeks ago, a colleague of mine Steven Murawski reached out and asked to meet at discuss why automation was important for me back when I hired him to work for me at a previous job. At that time he was a PowerShell MVP working at one of the local municipalities and I was the Vice President of IT for a Software as a Service firm with fortune 500 customers.
We met for lunch and he gave me more context on his question. He went on to explain that in his new role as a Cloud Developer Advocate he meets and talks with a lot of companies. He like myself prior to working at Microsoft has attended and spoke at a myriad of technical conferences. We have both heard and follow technology trends, he was trying to understand why my perspective was so much different than that of the CIOs, IT VPs and Directors he was meeting with. I had always joked with him that I knew I needed to learn PowerShell, but it was just easier to hire him.
When I hired him to help with PowerShell automation it was 2010, we were running Windows Server 2008 R2, and managing multiple environments with over 150 machines was a big job for a small IT department. We were always trying to do more with less, and automation is key to that. It removes a lot of human error on configurations, it allows processes to be easily repeatable by any of the staff and delivers consistency. Hiring someone who already was an expert in PowerShell gave us a huge advantage, rather than having all the other engineers ramp on the technology blindly, we had someone to guide and train us.
As we discussed the topic a few things came to light;
1. Know your Company’s Business, support it, help drive it, make informed choices.
My company was a triple-launch partner with Microsoft in Los Angeles for the Heroes Happen {Here} Launch in 2008 for Visual Studio, Windows Server, and SQL Server. I attended that event as a VIP, and during Steve Ballmer’s keynote he emphasized a vision called ‘Dynamic IT’.
Ballmer talked up Microsoft's "Dynamic IT" vision, which fits into four main topics that customers have been discussing with Microsoft: achieving agility and managing complexity; protecting information and controlling access; delivering business value; and making sure that IT professionals are "not the cobbler's children without shoes." (Source: https://www.cio.com/article/2437047/servers/ballmer-launches-windows-server-2008--lauds-user-base.html)
This was just one incarnation of the notion that Information Technology is not just a division of a company (usually one considered a cost center), but that IT serves the business and should be a partner to it. One sign of a successful company is one whose IT department is a valued partner in the success of the company. IT departments need to understand their company’s business and be optimized to help drive the company’s competitive edge. This is still true today with the adoption of SaaS and PaaS, use the commodity hosted solutions and invest your IT resources into the things that differentiate your company from its competitors. How many companies have email as their critical differentiator? Source that out to a service! The companies that don’t evolve are often the ones that don’t survive. Today we would call this a company’s Digital Transformation.
2. Stay current with versions of technology, Operating systems, Software packages.
We were different from most companies on how we used software. We evaluated software that was core to our business, Operating Systems, Database Management Systems, Development Platforms, etc. We made sure we stayed current on those systems, because the ‘secret sauce’ of our company. Our software was built directly on top of those. Often there were advancements in the platform that we used to leverage a technical advantage for the company. If we could use some new feature in Microsoft SQL Server that made our system run faster with less coding on our part, we did that. We built strong relationships with our software vendors and participated in pre-release programs continually. Third party tools were picked very carefully, when you are using the bleeding edge software platform you need to make sure that the other tools you pick can keep up.
You don’t want to be held hostage by a software vendor that won’t upgrade or doesn’t upgrade at the pace you need them to. This is especially critical for systems that are Core to your businesses survival and differentiation. Through a lot of the Windows Server releases System Center was always lagged behind, so it made it un-useable for my environment. We instead looked to PowerShell and automation to give us the ability to easily manage a lot of servers. Being on this leading edge also afforded us the ability to help fix problems or bugs that we uncovered while the development team is focused on getting the product released. We had fully tested our applications on the new platform and were able to confidently release our new software on or before the public release of the platform.
Does this mean that we ran everything in the place on pre-release software, heck no. We evaluated systems and picked the ones that made sense to the business to operate that way. For example, our core Financial system that our accounting department used, we kept it on the current version, but did so on a timeline that made sense for the business. We didn’t go and upgrade at a month or year end, but we stayed current. Technical debt for unmaintained systems is a huge problem. Software is generally not tested in a skip-a-version mentality, and if you think you can just go upgrade from version 4, to 5 then 6 without testing version 5 you also could be in for trouble.
3. Having solid tested and documented processes and as much automation as possible for whatever you are doing.
Because we did agile software development the idea of releasing to different environments was not foreign to us. We had Development, Test, User Acceptance Testing, and Production environments. If you release software on any frequent cadence you need to have documented well tested processes. Automation plays a key part of that, in our case we had a lot of Data, and most CI/CD pipelines don’t deal with stateful data well. i.e. updates to databases, moving database changes between environments. We had a checklist with steps that included automated and manual processes for every part of a deployment. If you are reading this, you may be thinking that this sounds a lot like DevOps. If you are also thinking that the infrastructure management is also incorporated into that process, you would be correct. When you approach IT from the point of Digital Transformation (IT with customer goals in mind), DevOps is how that happens.

Steven told me about companies that he has talked to and how many of them are just now finishing their server OS upgrade of 2008 to 2012/R2 to remain in mainstream support, and how for many of them it was a four-plus year project. The problem is Windows 2012/R2 is only under mainstream support until October 2018, and another project to go to 2016 for them will take another four years and has not been started. Having this monolithic approach will provide never-ending projects that don’t help your company transform. The pace of IT innovation is much faster; you need to have ways to help you keep up with that innovation. Automation is the key to removing bottlenecks and being able to respond to changes in an agile manner.
If you are an IT leader (or aspire to be one), keeping these three things in mind are critical to success. Without a true focus on your company goals, traditional IT metrics and behaviors can jeopardize business objectives. When we start to look at IT as a key component of the companies’ services or offerings; slow, fragile, and manual process starts to become even more unacceptable. IT needs to enable the business and be able to evolve with the needs of business, and that includes all the services it supports. IT needs to be part of the business not an anchor of technology.
So, you want to know a bit more about where to go? Here's a bit of light reading to get you started –
-
Phoenix Project – The fictional story of a DevOps transformation
-
The Goal – Lays out the basics of the Theory of Constraints and how to focus on the real goal
-
Critical Chain – Applies the Theory of Constraints to project management
-
The Art of Business Value – A critical discussion of how to identify business value from an IT org
-
A Seat at the Table - How senior IT leadership can become relevant in leading the company direction
MSteineke
Over the last few months I have run into similar configuration problems at a number of places. After the 4th or 5th time seeing the same issue I thought it deserved a blog post… Especially after I realized that I have also been making the same mistake on some of my own systems.
Block size is very important for performance for a number of server functions, particularly SQL server. There is a best practice article written in 2009 by Jimmy May and Denny Lee from Microsoft SQL CAT (Now Azure CAT). http://technet.microsoft.com/en-us/library/dd758814(v=SQL.100).aspx Jimmy also updated his blog a few months ago reiterating how important this still is for the current versions of SQL. http://blogs.msdn.com/b/jimmymay/archive/2014/03/14/disk-partition-alignment-for-windows-server-2012-sql-server-2012-and-sql-server-2014.aspx
I’m sure a few of you are thinking, yes we have been doing this for a long time, we know best practice is to use 64k block for SQL. How many of you are virtualizing your SQL Servers? So you make your VHDx and format it with a 64k block. You’re good right? Maybe not. If you are putting those VHDx files on a Cluster Shared Volume on your Hyper-V cluster, what is that physical volume’s block size?
So for those that don’t know how to check this, all you need to do is run CHKDSK (from an elevated command prompt) to check the block size. If you go run this you will probably end up with something like I have here on my workstation. Where the block size default is 4096 bytes.

To make this work with a CSV volume, since it does not have a drive letter the syntax is: chkdsk.exe <CSV mount point name> http://blogs.msdn.com/b/clustering/archive/2014/01/02/10486462.aspx
I thought that there also had to be some PowerShell to help with this, and iterate through all the CSV volumes on the cluster, because there are probably more than one of them right. I searched for a while and came up with a bunch of articles on how to check free space on the CSV, which is useful, but nothing that said what the block size was. So I then reached out to my friend and PowerShell MVP Steven Murawski for some help. About 4 minutes later he sent me some PowerShell to help with my problem:
$ComputerName = '.'
$wql = "SELECT Label, Blocksize, Name FROM Win32_Volume WHERE FileSystem='NTFS'"
Get-WmiObject -Query $wql -ComputerName $ComputerName | Select-Object Label, Blocksize, Name
This was almost exactly what I wanted, but it did not show me the block size for the CSV volumes, but it did for all the NTFS volumes. CSV volumes, while they may have started as NTFS, when they are converted to a CSV, the format is referred to as CSVFS, so with a little tweak to what he gave me:
$ComputerName = '.'
$wql = "SELECT Label, Blocksize, Name FROM Win32_Volume WHERE FileSystem='CSVFS'"
Get-WmiObject -Query $wql -ComputerName $ComputerName | Select-Object Label, Blocksize, Name
Now this will list all the CSV volumes in a cluster and their Block Size.

So now that I can easily check that block size, what do I really want it to be? Well for SQL Server you want it to be the same best practice of 64k. For other workload this seems to be the size that makes sense to use as well. There are a lot of articles out there for specific hardware, and what is best for them. There is no Best Practice for Hyper-V that I have found from Microsoft, there are a lot of comments on what to use, and they all point to using 64k as the volumes are usually RAID. That said if you read all of the article Jimmy and Denny wrote, it states:
“An appropriate value for most installations should be 65,536 bytes (that is, 64 KB) for partitions on which SQL Server data or log files reside. In many cases, this is the same size for Analysis Services data or log files, but there are times where 32 KB provides better performance. To determine the right size, you will need to do performance testing with your workload comparing the two different block sizes.”
Keeping this in mind you may need to have volumes that are formatted with different block sizes for specific workloads. You will need to test your specific IO scenario if you want to optimize the system. And you should make sure that at all levels you are using the best block size for your workload. For those who don’t know how to check IO workload, one popular tool you can use is SQLIO. http://www.microsoft.com/en-us/download/details.aspx?id=20163
MSteineke
 I am speaking with Microsoft at the 2014 Dell Users Forum in Florida. http://www.dellenterpriseforum.net/information.php The event is located Ocean side at the Westin Diplomat Resort & Spa. I can't wait to check out the event!
I am speaking with Microsoft at the 2014 Dell Users Forum in Florida. http://www.dellenterpriseforum.net/information.php The event is located Ocean side at the Westin Diplomat Resort & Spa. I can't wait to check out the event!
MSteineke

Volunteering at Oshkosh this year was a great time! I was able to catch up with friends, shoot some beautiful Airplanes and captured some amazing images. I hope to post a gallery by next week some time, after I can sit down and edit my files. Here is a photo shot from a camera phone by Phil High, of one of my Air to Air missions.
MSteineke
As some of you know, I have had a ton of problems with Direct Access and my new fancy Lenovo Helix. I decided that the best way to determine what driver or application that came pre-loaded was causing the problems, was to just start with a fresh base install of Windows 8 Enterprise, and add from there. Simple, right, I've loaded or reloaded hundreds or possibly thousands of workstations - not so much... after a couple hours fooling around with the UEFI BIOS, searching and reading, and getting it almost to work... I finally went to a backup plan, call someone who I know has reloaded a UEFI BIOS machine, and ask, "What's the trick?" So I ping a friend of mine at Microsoft, Larry Clarkin @larryclarkin, after a few minutes he had solved my issue, and has written a blog post on it, http://eraserandcrowbar.com/2013/06/19/Windows8UEFISecureBootOnCleanInstall.aspx
Hopefully this will alleviate frustration from others who are having the same problem!
MSteineke
I had the pleasure of speaking today at an event called Storage Solutions for the Private Cloud, in Mountain View, CA. The event was held at the Computer History Museum.

I got to see a lot of computer history, from the Eniac, and Univac to the Cray1 & 2. Gaming systems, PDAs, you name it, it is probably there.
The event was a great time, and the Museum was also really cool.
MSteineke
I have been working with Infiniband cards in a few different Hyper-V clusters. I did some work with Hyper-V over SMB on Windows 2012 Beta, and it was very impressive. While waiting for my production IB switches, I have been testing Live Migration on a Cluster-in-a-Box with 2 IB cards with basically a crossover cable between them. The migration performance is ridiculously fast. I have 50 1GB vm's, and I can migrate them from node to node in under 20 seconds. The IB network interface hits about 30 Mb/sec.
I am going to test with different numbers and sizes of VM's and I will share the results! I think the results are going to be very interesting.
MSteineke

So I received my Microsoft Surface today via FedEx... The device is pretty nice, although I already have something that I think would have made the product much better. One of the most useful things I think you can do with a portable easy to use device like this tablet is email. Phones and slates all have mail clients that are good for reading mail, and occasionally sending one. Delete also a really helpful feature. When I bought my iPad (yes I own one) I thought, great, I can crank through a bunch of email while on planes, etc... Not really the case with how Apple implemented Exchange activesync. I thought Surface, with Windows RT - perfect I will have Outlook, not the case I should have read the specs closer... Only the Metro Mail App, it works, but it is nothing like using Outlook, looks like I am now waiting for the Surface with Windows 8 Pro, so I can have my slate, and my Outlook too.
MSteineke
I'm busy finishing my presentation for That Conference next week, on Building a Private Cloud with Windows 2012 Hyper-V.

Hope to see you there! August 13th -15th
MSteineke
There are a few ways you can configure MSDTC when you need to use it on a SQL Fail over Cluster Instance. We have applications that need to commit transactions across multiple SQL FCIs so a Clustered DTC is necessary. If you only have 1 active SQL node, it is pretty easy, you create a clustered DTC, which lives as its own clustered Application.
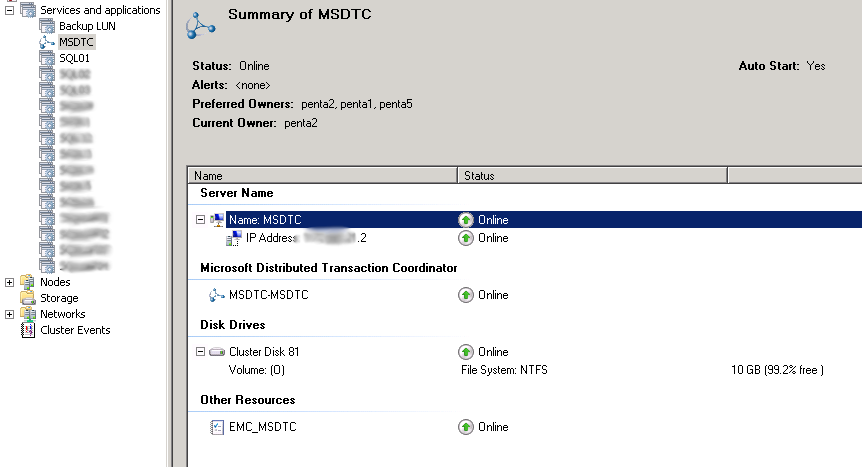
As you can see MSDTC has an IP resource, a name resource and a Disk resource in the cluster, and the disk resource is mounted as a drive letter.
Although there are a few ways that are supposed to work to create multiple MS DTC instances in a cluster, there is only one that I have found to work reliably. That way is to create an MSDTC service inside each SQL application.
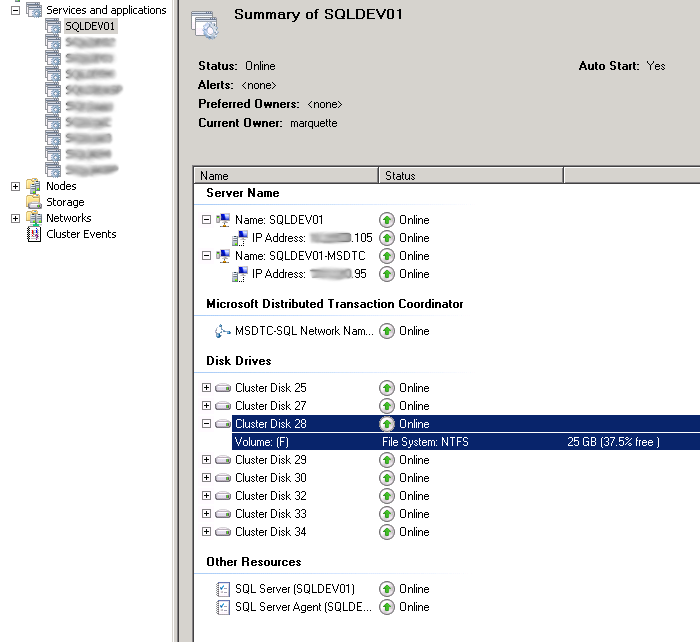
As you can see above there are all the same resources that are in a single clustered MSDTC, with a few modifications. I have shared the Drive Volume F with the SQL System databases, to not waste another drive letter, since SQL needs to use one anyway. You need to make sure that you have enough space to hold the databases and DTC. In our configurations we also move TempDB to another LUN, by default it would be in this location and it would be easy to run out of disk. I have also added a dependency for the SQL Service on the MSDTC Service to ensure that the MSDTC instance is running before SQL starts. SQL will then always pick the MSDTC that is running in the same cluster application. I have found to make this work, you must have a unique name and IP for each MSDTC contrary to documentation that says you can share a name and IP.